シグモイドとReLU、何が違うのか
ニューラルネットワークを構築する際、活性化関数の選択は学習の成否を左右します。シグモイド関数は古くから使われてきましたが、現在の深層学習ではReLU関数が主流です。この記事では、2026年4月9日にMarkTechPostが公開した実験レポートを基に、両者の違いを分かりやすく解説します。
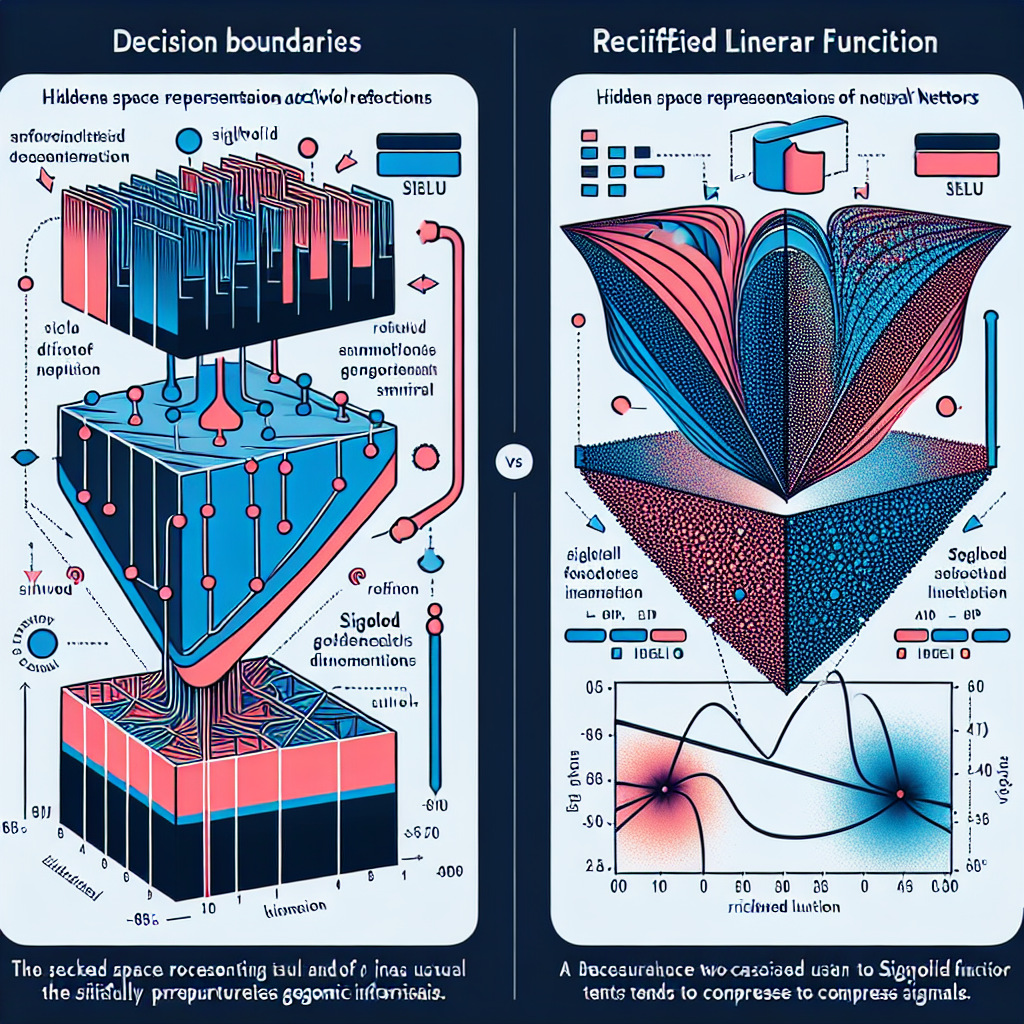
シグモイド関数は、入力された数値をすべて0から1の範囲に圧縮します。一見便利に思えますが、この圧縮が問題を引き起こします。たとえば、決定境界から離れた値は区別がつかなくなり、層を重ねるほど情報が失われていくのです。一方、ReLU関数は正の値をそのまま保持するため、距離情報がネットワーク全体に伝わります。
実験内容と設定
実験では、scikit-learnのmake_moons関数で生成した合成データセット(400サンプル、ノイズ0.18)を使用しました。データは標準化され、訓練用とテスト用に分割されています。ネットワークは3層構造で、隠れ層が2つ、出力層が1つです。損失関数には二項交差エントロピーを採用し、800エポックにわたって訓練しました。
初期化戦略も工夫されています。ReLUにはHe初期化、シグモイドにはXavier初期化を使い、それぞれに最適な条件を整えました。学習率は0.05、バッチサイズは64で、ミニバッチ勾配降下法を使って最適化しています。
損失曲線から見える差
訓練中の損失曲線を比較すると、違いは明白です。シグモイド関数を使ったモデルは、最初こそ改善しますが、エポック400付近で約0.28に停滞し、その後ほとんど進展がありませんでした。対照的に、ReLU関数を使ったモデルは継続的に損失を減少させ、エポック800で約0.03に到達しています。
この差は、決定境界の学習にも表れます。シグモイドネットワークはほぼ線形の境界しか学習できず、テスト精度は約79%でした。データの曲線構造を捉えられなかったのです。一方、ReLUネットワークは非線形で適応的な境界を学習し、テスト精度は約96%に達しました。データ分布に密接に従った結果です。
層ごとの信号トレースで分かること
決定境界から遠い点を追跡すると、シグモイドとReLUの挙動の違いが鮮明になります。シグモイド関数では、最初の層で2.0だった値が0.3に圧縮され、深い層でも0.5から0.6の狭い範囲に留まりました。これでは、どの入力が重要かを判別できません。
ReLU関数では、値の大きさが保持され、最終層では9から20の範囲に到達しています。この特性により、ネットワークは入力の違いを深い層まで伝えられるのです。
隠れ空間の分析
隠れ層での表現を可視化すると、さらに興味深い結果が見えてきます。シグモイドネットワークでは、両クラスが重なり合う領域に崩壊しました。標準偏差は層1で0.26、層2で0.19に低下しており、情報の圧縮が進んでいます。
ReLUネットワークでは、層1で標準偏差1.15、層2で1.67に拡張されています。クラスは明確に分離可能で、深い層ほど表現力が高まる様子が確認できました。
フリーランスへの影響
この実験結果は、フリーランスでAIモデルを開発する方にとって、実践的な指針となります。カスタムモデルを構築する際、活性化関数の選択は精度に直結します。シグモイドを選ぶと、深い層を重ねても表現力が伸びず、学習が停滞するリスクがあります。
ReLUを選べば、同じ計算コストでより高い精度を狙えます。特に、画像認識や自然言語処理など、深層学習が必要なタスクでは、ReLUが標準的な選択です。もしクライアントから「なぜこの関数を使ったのか」と尋ねられたら、この実験データを根拠に説明できます。
ただし、ReLUにも欠点があります。負の値はすべてゼロになるため、一部のニューロンが学習中に死んでしまうことがあります。この問題を避けたい場合は、Leaky ReLUやELUといった改良版も検討する価値があります。
まとめ
シグモイドとReLUの違いは、理論だけでなく実験でも明確です。ReLUは情報の保持に優れ、深い層でも高い表現力を維持します。フリーランスでモデル開発をする際は、ReLUを第一選択とし、特殊な要件がある場合のみ他の関数を検討するのが現実的です。詳細なコードや可視化は、元記事で公開されているGitHubリポジトリで確認できます。


コメント