従来のループ型AIが抱えていた問題
AIモデルを小さく保ちながら性能を上げる方法として、同じ処理層を何度も通過させる「ループ型」のアプローチは以前から研究されてきました。パラメータ数を増やさずに計算量を増やせるため、メモリに制約があるスマートフォンやエッジデバイスでの利用に適しています。
しかし、この手法には大きな壁がありました。訓練中に「残差状態爆発」と呼ばれる現象が起き、学習が不安定になってしまうのです。特にRDMなどの既存モデルでは、ループを重ねるごとに内部の数値が制御不能に膨らみ、損失が急激に跳ね上がる「損失スパイク」が頻発していました。そのため、理論上は魅力的でも実用化が難しい状態が続いていたのです。
制御理論で安定性を保証する設計
Parcaeはこの問題を、制御理論という数学的手法を使って根本から解決しました。モデルを「非線形時変動力学系」として定式化し、スペクトル規範と呼ばれる指標をρ(Ā) < 1に保つ設計を採用しています。これにより、ループを何度繰り返しても内部状態が安定したまま保たれます。
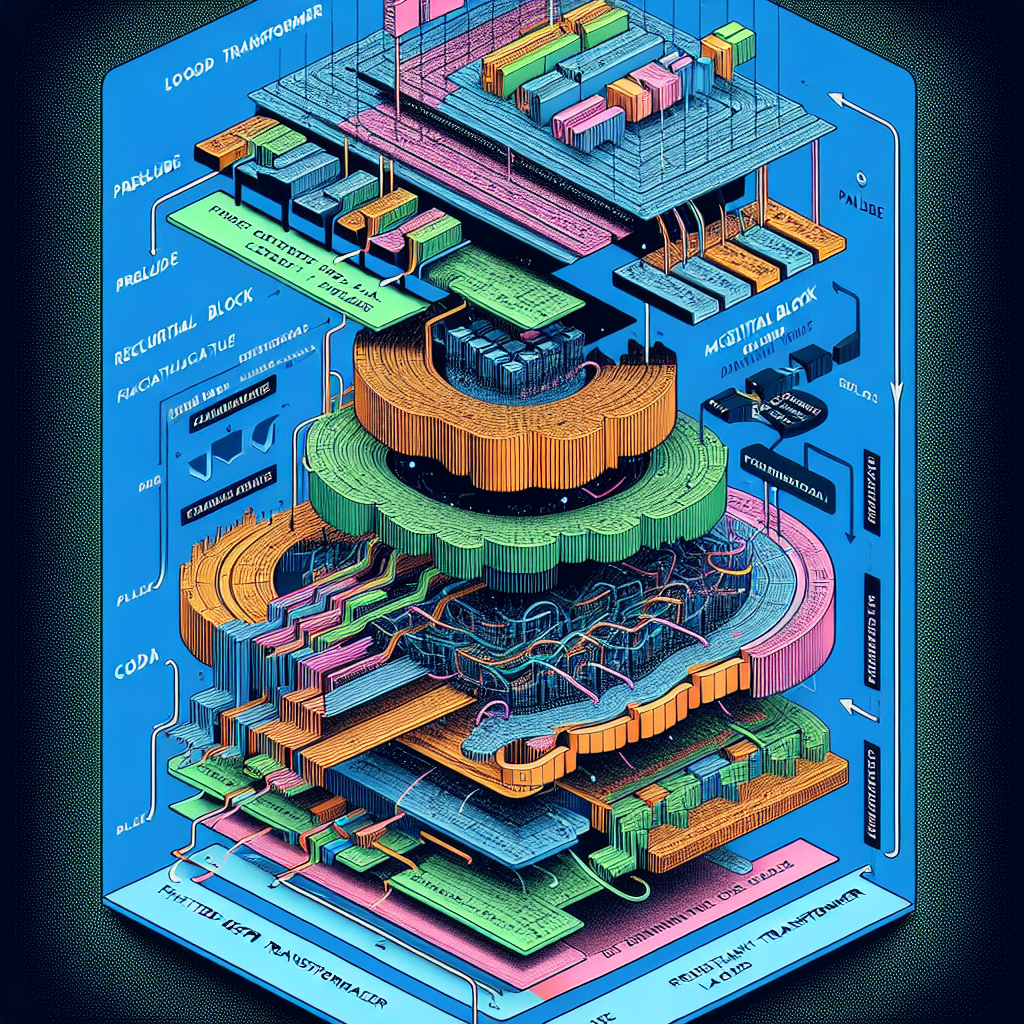
具体的には、モデルを3つの機能ブロックに分けています。入力を受け取る「プリリュード」、繰り返し処理を行う「リカレントブロック」、最終出力を生成する「コーダ」です。この中央ループ設計によって、従来の加算ベース(限界安定)や連結投影法(不安定)とは異なり、設計段階で安定性が数学的に保証されています。
研究チームは継続形式を離散化する際に、ゼロ次ホールドとEulerスキームを採用し、実装レベルでも安定性を維持しました。これにより、大規模データセットでの長時間訓練でも、損失スパイクが起きない安定した学習が可能になったのです。
実際の性能はどれくらい向上したのか
論文では複数のベンチマークで性能が検証されています。Huginnデータセットでの検証では、従来のループ型モデルと比べて困惑度(低いほど優秀)が最大6.3%削減されました。350Mスケールでは10.76から10.09に、100Mスケールでは13.59から4.23へと大幅に改善しています。
より興味深いのは、標準的なTransformerとの比較です。1.3Bパラメータ、104Bトークンでトレーニングした場合、Parcaeは固定深度Transformerをベンチマークスコアで2.99ポイント上回りました。さらに、770MパラメータのParcaeモデルが、1.3Bパラメータの標準Transformerと同等の品質を達成しています。つまり、約半分のサイズで同じ性能を出せるわけです。
WikiTextでの困惑度も最大9.1%改善し、ゼロショットベンチマークでは精度が1.8ポイント向上しました。パラメータ効率の観点では、Transformerの2倍のサイズが持つ品質の87.5%を達成しており、メモリ制約下での実用性が証明されています。
初のループ最適化スケーリング則
Parcaeのもう一つの貢献は、ループ型モデルに関する予測可能なスケーリング則を初めて確立したことです。140Mおよび370Mスケールでの実験により、計算最適なトレーニングでは平均リカレンス回数とトレーニングトークン数を一致して増やすべきことが示されました。
具体的には、最適なループ回数は計算予算のC^0.40に、最適トークン数はC^0.78にスケールします。また、推論時にループ数を増やすと、性能は飽和指数減衰に従うことも分かりました。この法則により、予算内で最も効率的なモデル設計が可能になり、ループ最適化だけでベンチマークスコアが1.2~2.0ポイント向上しています。
どんな場面で使えるのか
Parcaeが特に威力を発揮するのは、メモリに制約があるデバイス上でのAI実行です。例えばスマートフォンアプリで高性能な言語モデルを動かしたい場合、通常は数GBのメモリを必要とするため、モデルサイズの削減が必須です。Parcaeなら同じ品質を半分のサイズで実現できるため、オンデバイスAIの選択肢が広がります。
また、推論デプロイメントのコスト削減にも効果的です。クラウドでAI APIを提供する際、メモリ使用量が半分になれば、同じサーバーで2倍のリクエストを処理できます。サーバーレス環境でのコールドスタート時間も短縮されるため、レスポンスの速さが求められるサービスにも適しています。
さらに、エッジコンピューティング環境での活用も見込まれます。IoTデバイスやロボットなど、リアルタイム処理が必要で通信遅延を避けたい場面では、軽量でありながら高性能なモデルが重宝されます。
フリーランスへの影響
現時点でParcaeは研究段階のアーキテクチャであり、すぐに実務で使えるツールではありません。論文とモデルの重みはarxivやHugging Faceで公開されていますが、商用サービスとして提供されているわけではないため、エンジニアでない限り直接触れる機会は少ないでしょう。
ただし、この技術が実用化されれば、フリーランスの作業環境に間接的な恩恵をもたらす可能性があります。例えば、現在クラウドAPIでしか使えない高性能AIが、ローカルPCやスマートフォンでも動くようになれば、通信コストや月額料金を気にせず使えるようになります。オフラインでの作業も可能になるため、移動中や通信環境が悪い場所でも生産性を保てるでしょう。
また、AI APIを提供する企業がParcae型のアーキテクチャを採用すれば、サービスの価格が下がる可能性もあります。メモリ効率が2倍になれば、インフラコストが半減し、その分が利用料に反映されるかもしれません。特に画像生成や動画生成など、大量のトークンを消費するタスクでは、コスト削減の効果が大きくなります。
開発者やノーコードツールを活用するフリーランスにとっては、Hugging Faceで公開されているモデルを試してみる価値はあります。Together.aiのプラットフォームでも技術詳細が公開されているため、将来的に自分のワークフローに組み込む準備として、情報をチェックしておくのは悪くありません。
まとめ
Parcaeは、ループ型AIの訓練安定性を解決した点で技術的に重要なブレークスルーですが、現時点では研究段階です。フリーランスが今すぐ何かアクションを取る必要はありませんが、将来的にオンデバイスAIやコスト削減の形で恩恵を受ける可能性があります。
もしあなたがAI開発に関わっているなら、Hugging FaceやTogether.aiで公開されている資料を確認してみるのも良いでしょう。そうでない場合は、この技術が商用サービスに組み込まれるのを待つのが現実的です。AI業界の動向に興味があるなら、定期的にチェックしておく程度で十分です。


コメント