10億枚の人物画像で学習したAIモデル
Sapiens2は、人間の姿や動きを理解することに特化したAIモデルです。Metaの研究チームは「Humans-1B」という新しいデータセットを作成し、約40億枚の画像から厳選した10億枚の人物画像で学習させました。このデータセットには、最低でも384ピクセル以上の解像度で人物が写っている画像だけが含まれており、画質の低い写真や重複画像は取り除かれています。
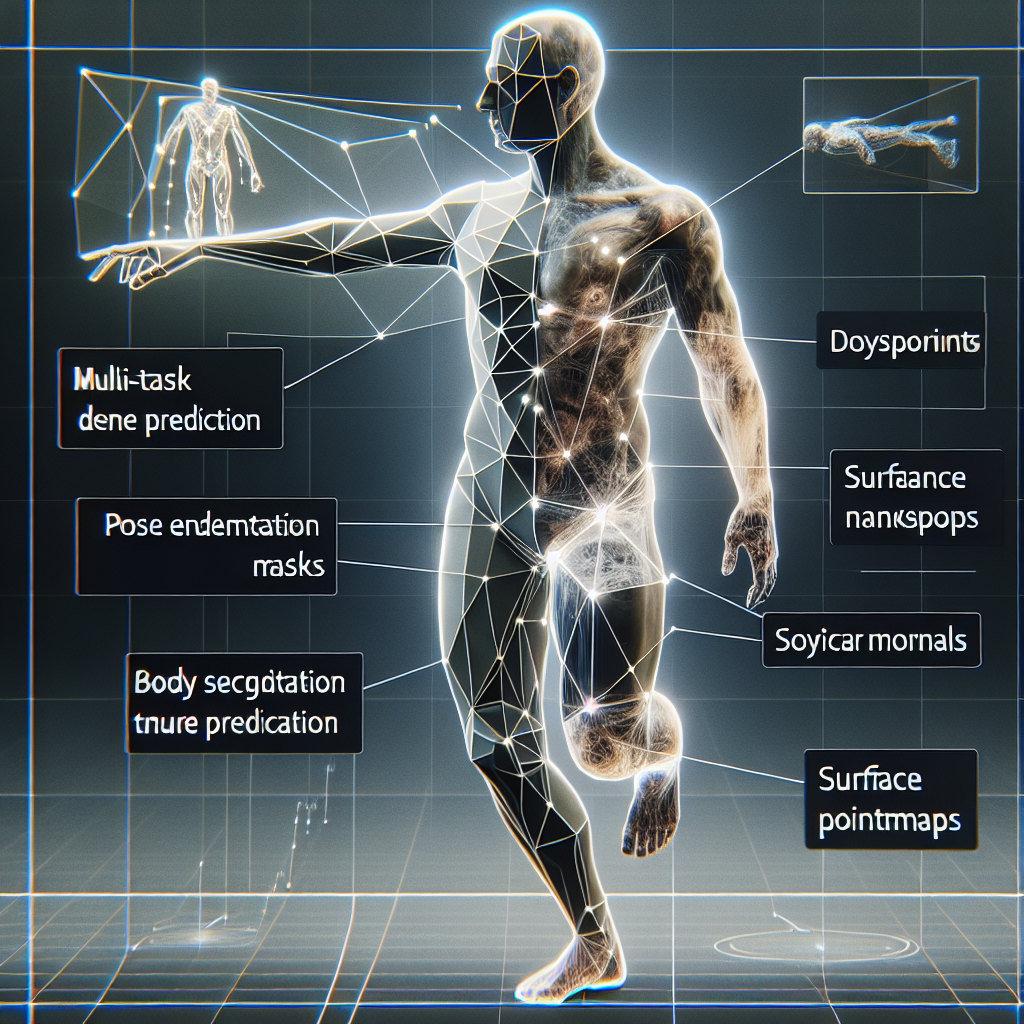
このモデルが特徴的なのは、人物の分析に必要な複数のタスクを一つのシステムで処理できる点です。従来は姿勢推定、体のパーツ分け、3D形状の推測など、それぞれ別のツールを使う必要がありました。Sapiens2ではこれらを統合的に扱えるため、作業の手間が減ります。
モデルのサイズは4種類用意されており、0.4B(4億)、0.8B(8億)、1B(10億)、5B(50億)パラメータから選べます。数字が大きいほど精度が高くなりますが、処理に必要な計算能力も増えます。自分の作業環境やニーズに合わせて選択できる設計です。
具体的に何ができるのか
Sapiens2が対応している主な機能は5つあります。一つ目は姿勢推定です。人物の全身から顔の細かい表情、指先の動きまで、合計308か所のポイントを自動で検出します。たとえば、動画編集でモーションキャプチャのような効果を加えたいとき、手作業でポイントを打つ必要がなくなります。
二つ目は体のパーツ分けです。顔、腕、足、服など29種類の部位を自動で識別し、ピクセル単位で分類してくれます。人物写真の背景だけを変えたいときや、服の色だけを調整したいとき、選択範囲を手作業で作る手間が省けます。
三つ目は3Dポイントマップの推定です。平面の写真から、人物の立体的な形状を推測してくれます。ARコンテンツや3Dモデル制作の下準備として使えそうです。四つ目は表面の向きを示す法線推定で、照明効果の調整に役立ちます。五つ目はアルベド推定といって、照明の影響を取り除いた本来の肌や服の色を復元する機能です。
これらの機能は、それぞれ独立して使うこともできますし、組み合わせて複雑な編集作業に活用することもできます。たとえば写真のレタッチ作業で、人物の姿勢を検出してから体のパーツごとに色調整を行い、最後に照明を整えるといった一連の流れを自動化できるかもしれません。
従来のツールと比べた性能
MetaはSapiens2の性能を、既存のAIモデルと比較したデータも公開しています。姿勢推定の精度を示すmAPという指標では、最大モデルのSapiens2-5Bが82.3を記録しました。前世代のSapiens-2Bが78.3だったので、約4ポイント向上しています。
体のパーツ分けでは、最小モデルのSapiens2-0.4Bでも79.5という数値を出しており、これは従来の専門モデルと比べて21.3ポイント高い結果です。最大モデルでは82.5まで達しています。表面の向き推定では平均誤差が6.73度と、以前の最高性能だったDAViD-Lの10.73度を大きく下回りました。
注目すべきは、モデルの本体部分を変更せずに各タスク用の軽量な追加部分だけを学習させる「密集プローブ評価」でも、他の汎用AIモデルを上回った点です。これは、人物画像の理解に特化した学習が効果的だったことを示しています。
高解像度への対応
Sapiens2は標準で1024×1024ピクセルの画像に対応していますが、一部のモデルは4K解像度にも対応しています。高解像度モデルでは「階層的ウィンドウ注意」という技術を使い、画像の細部と全体を効率的に処理する仕組みが組み込まれています。これにより、大きな画像でも処理速度を保ちながら精度を維持できるようになっています。
フリーランスの実務にどう影響するか
このモデルが実用化されれば、人物写真や動画を扱う作業の多くが効率化されます。特に影響を受けそうなのは、写真のレタッチ業務、動画編集、グラフィックデザイン、3Dコンテンツ制作などの分野です。
たとえばポートレート写真の編集では、肌のトーン調整や体型補正などの作業を部分的に自動化できるかもしれません。現在はPhotoshopなどで手作業で選択範囲を作っている部分が、AIが自動で判別した領域をベースにできれば、作業時間は確実に短縮されます。
動画制作では、人物の動きをトラッキングする作業が楽になります。モーショングラフィックスやエフェクトを人物に追従させるとき、フレームごとに位置を調整する手間が減るでしょう。ただし、現時点では動画への適用については詳しい情報がなく、静止画での性能が中心です。
一方で、このモデルを実務に組み込むにはある程度の技術知識が必要です。HuggingFaceでモデルは公開されていますが、Photoshopのプラグインのように簡単に使えるわけではありません。PythonやAPIの知識がある方、あるいは既存のツールに組み込めるエンジニアと協力できる環境でないと、すぐには活用しづらいでしょう。
収益面では、作業時間の短縮が直接的なメリットになります。1枚の写真編集にかかる時間が半分になれば、同じ時間でこなせる案件数は倍になります。ただし、競合も同じツールを使える環境になるため、差別化のポイントは技術の使いこなしやクリエイティブな提案力に移っていくかもしれません。
注意しておきたい点
Sapiens2は研究段階のモデルであり、商用利用についてのライセンス条件は確認が必要です。HuggingFaceでの公開ページやGitHubリポジトリに詳細が記載されているはずですが、クライアントワークで使う前には必ず利用規約を確認してください。
また、AIによる人物認識には倫理的な配慮も求められます。特に顔や体の詳細な分析は、プライバシーや偏見の問題と隣り合わせです。どのような画像に使うか、クライアントや被写体の同意は得られているかなど、慎重な判断が必要になる場面もあるでしょう。
技術的な制限としては、処理に必要な計算リソースがあります。特に5Bモデルは高性能ですが、それなりのGPU環境がないと快適に動作しないかもしれません。まずは小さいモデルで試してから、必要に応じてスケールアップするのが現実的です。
今後の展開と様子見のポイント
Metaは今回、モデルとデモを公開しただけでなく、論文やGitHubリポジトリも提供しています。これは開発者コミュニティがこの技術をベースに新しいツールを作ることを想定しているからです。今後数か月で、Sapiens2を組み込んだ使いやすいアプリやプラグインが登場する可能性があります。
フリーランスとして注目しておきたいのは、PhotoshopやDaVinci Resolveといった主要ツールへの統合です。Adobe Senseiのような既存のAI機能に、Sapiens2のような専門モデルが組み込まれれば、特別な知識がなくても恩恵を受けられます。そうした動きが出てくるまでは、無理に自分で導入する必要はないかもしれません。
一方で、技術に詳しい方や、差別化を図りたい方は、今のうちに試しておく価値があります。HuggingFaceのデモで動作を確認するだけでも、どんな処理が可能かイメージが湧きます。実際にモデルを動かせる環境があれば、自分の業務フローのどこに組み込めるか検証してみるのもいいでしょう。
まとめ
Sapiens2は、人物画像の分析に特化した高性能なAIモデルです。姿勢推定、体のパーツ分け、3D形状の推測など、複数の機能を一つのシステムで扱えます。写真や動画を扱うフリーランスにとって、作業効率を上げる可能性を持ったツールですが、現時点では技術的なハードルがあります。すぐに導入するかどうかは、自分の技術レベルと業務内容次第です。まずはHuggingFaceのデモで動作を確認し、主要ツールへの統合を待つのが現実的な選択肢でしょう。興味がある方は、公式のGitHubリポジトリや論文で詳細を確認してみてください。
参考リンク:Sapiens2 on HuggingFace


コメント