表データ分析の常識が変わる
これまで、エクセルやCSVファイルのようなタビュラーデータ(表形式のデータ)を機械学習で分析する際は、XGBoostやCatBoostといったツールを使うのが一般的でした。ただ、これらのツールは高性能な反面、データごとに最適な設定を見つけるための「ハイパーパラメータチューニング」という作業が必要で、初心者には敷居が高く、経験者でも時間がかかる作業でした。
TabPFNは、この面倒な工程をスキップできる新しいアプローチを採用しています。数百万の合成データセットで事前に学習済みなので、新しいデータを渡すだけで、自動的に最適な予測モデルを構築してくれます。大規模言語モデルがプロンプトだけで文章を生成するのと似た仕組みです。
実際のパフォーマンスはどうなのか
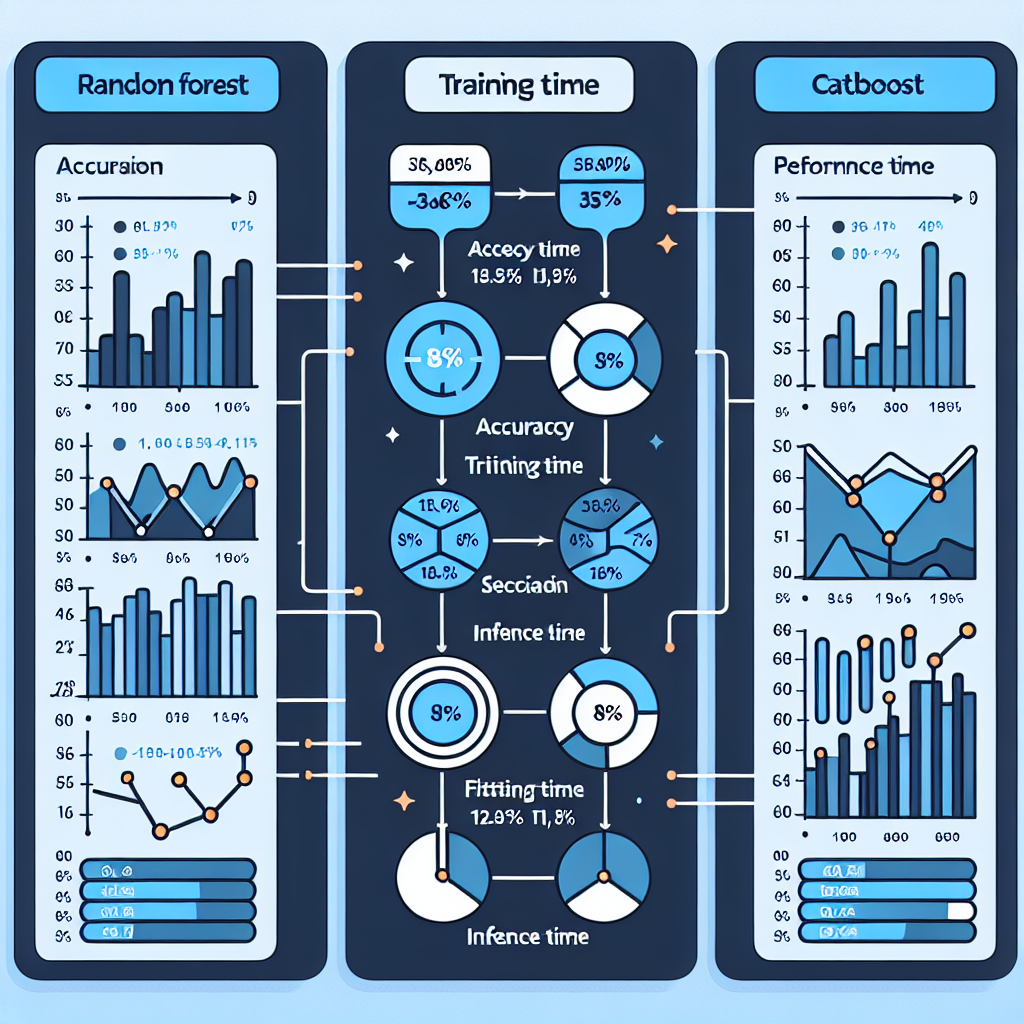
開発チームが公開した実験結果によると、TabPFNの精度は98.8%で、Random Forest(95.5%)やCatBoost(96.7%)を上回りました。さらに注目すべきは、モデルの準備時間(フィット時間)がわずか0.47秒だった点です。Random Forestは9.56秒、CatBoostは8.15秒かかっていたので、約20分の1のスピードです。
ただし、推論時間(予測を出すまでの時間)は2.21秒と、CatBoostの0.0119秒と比べてかなり遅くなっています。これは、TabPFNが推論時にトレーニングデータとテストデータを一緒に処理する仕組みのためです。リアルタイムで瞬時に予測が必要なアプリケーション(例えば不正検知システム)には向いていませんが、分析レポート作成や顧客セグメント分類など、数秒の遅延が問題にならない用途では十分実用的です。
フリーランスの実務でどう使えるか
たとえば、クライアントから「この顧客リストから購入見込みの高い人を抽出してほしい」と依頼されたとします。従来なら、データの前処理、モデルの選定、パラメータ調整、精度検証という工程を経て、早くても半日はかかる作業でした。
TabPFNを使えば、データを読み込んでAPIを叩くだけで、数分で予測結果が得られます。しかも精度は従来の手法と同等かそれ以上です。クライアントへの納品スピードが上がれば、同じ時間でより多くの案件を受けられるようになります。
また、TabPFNには「蒸留機能」があり、予測ロジックを小型のニューラルネットワークやツリーモデルに変換できます。これにより、最初はTabPFNで高精度なモデルを作り、本番環境では軽量版を使うといった使い分けも可能です。
導入のハードルと注意点
TabPFNを使うには、専用のAPIキーが必要です。公式サイト(https://ux.priorlabs.ai/home)でアカウントを作成すれば取得できます。料金体系は記事公開時点で明示されていませんが、API型のサービスなので従量課金制になる可能性が高いでしょう。
また、現時点では数百万行規模のデータに対応していますが、それ以上の超大規模データや、リアルタイム性が求められる用途には向いていません。あくまで「開発時間を最小化したい」「迅速に実験したい」というニーズに特化したツールです。
対応しているデータの種類
TabPFNが得意とするのは、医療記録、金融取引、顧客データ、売上データなど、構造化された表形式のデータです。画像や音声、自然言語のような非構造化データには対応していません。
フリーランスへの影響
データ分析を仕事にしているフリーランスにとって、TabPFNは作業時間の大幅な短縮につながります。特に、複数のクライアントから似たような分析依頼が来る場合、毎回ゼロからモデルを構築する手間が省けるのは大きなメリットです。
一方で、推論速度の遅さから、リアルタイムシステムの開発案件には使えません。また、API依存のツールなので、オフライン環境やセキュリティの厳しいクライアント案件では利用できない可能性があります。
収益面では、納品スピードが上がることで時給換算の効率が改善します。ただし、TabPFNが普及すれば、データ分析の単価が下がる可能性もあります。今後は「速く正確に分析できる」だけでなく、「データから何を読み取り、どう提案するか」というコンサルティング要素がより重要になるでしょう。
まとめ
TabPFNは、表データ分析の作業時間を劇的に短縮できる可能性を秘めたツールです。すでにデータ分析の案件を受けている方は、APIキーを取得して小規模なプロジェクトで試してみる価値があります。ただし、推論速度の制約があるため、すべての案件に使えるわけではありません。まずは自分の案件内容と照らし合わせて、導入の是非を判断するのが良いでしょう。
参考リンク:TabPFN公式サイト https://ux.priorlabs.ai/home


コメント