なぜ今、軽量OCRモデルが注目されるのか
OCR(光学文字認識)は、画像やPDFから文字情報を取り出す技術です。請求書のデータ入力、名刺管理、海外文献の翻訳前処理など、フリーランスの実務でも使う場面は多いでしょう。ただ、従来のOCRツールには弱点がありました。単純なテキストは読み取れても、表や数式が混在した文書、複雑なレイアウトのドキュメントになると途端に精度が落ちるのです。
一方で、ChatGPTやGeminiのような大規模なマルチモーダルAIは文書理解能力が高いものの、処理コストが高く、大量の文書を扱うには向いていません。特にフリーランスや小規模事業者にとって、月々の利用料金は無視できない要素です。
GLM-OCRは、こうした「精度」と「コスト」の間にある溝を埋めるために開発されました。0.9Bパラメータという小型サイズながら、複雑な文書解析に特化しており、エッジ環境や大量処理でも実用的な速度とコストを実現しています。
GLM-OCRの主な機能と仕組み
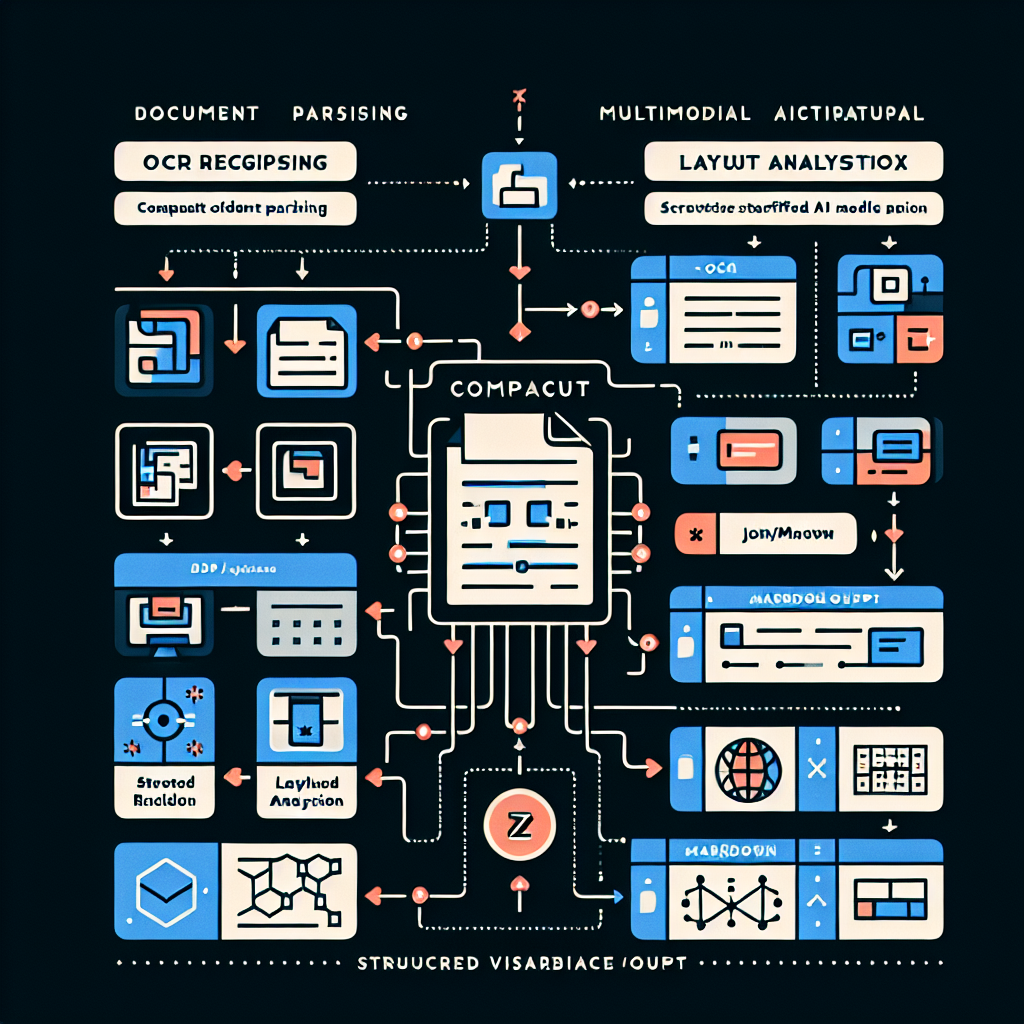
GLM-OCRは、画像を理解するビジョンエンコーダーと、テキストを生成する言語デコーダーを組み合わせた構造を持っています。0.4BのCogVitビジョンエンコーダーと0.5BのGLM言語デコーダーという、いずれも軽量なモジュールで構成されているため、動作が軽快です。
特徴的なのは、Multi-Token Prediction(MTP)という技術を採用している点です。通常のAIモデルは1ステップで1トークンずつ生成しますが、GLM-OCRは平均5.2トークンを一度に生成します。これにより処理速度が約50%向上し、大量の文書を扱う場合でも待ち時間が短くなります。たとえば、100ページのPDFを処理する場合、従来なら数分かかっていた作業が半分程度の時間で完了するイメージです。
処理は二段階で行われます。第一段階ではPP-DocLayout-V3というツールでページのレイアウトを解析し、見出し、本文、表、画像といった要素を識別します。第二段階では、それぞれの領域を並列に認識し、Markdown形式やJSON形式で構造化された出力を生成します。このため、単にテキストを抜き出すだけでなく、文書の構造を保ったまま情報を取り出せるのです。
対応する文書フォーマット
GLM-OCRは以下のような処理に対応しています。
- 通常のテキスト認識(手書き文字を含む)
- 数式の転写(LaTeX形式で出力可能)
- 表の構造復元(セル結合やヘッダーを保持)
- キー情報抽出(請求書から日付・金額・宛名などを自動抽出)
たとえば、海外クライアントから送られてきた英語の契約書PDFをアップロードすれば、条項ごとに整理されたJSON形式で出力されます。また、手書きのメモや古い書類をスキャンした画像も、かなりの精度で読み取れるとされています。
他のOCRツールと何が違うのか
従来の代表的なOCRツールとしては、Google Cloud VisionやAmazon Textract、国内ではAI-OCRサービスなどがあります。これらは平文のテキスト認識には強いのですが、複雑なレイアウトや数式、表の認識では精度が不安定になりがちです。また、APIの従量課金が高めに設定されているケースも多く、月に数百ページ処理するだけで数千円〜数万円のコストがかかることもあります。
一方、ChatGPT PlusやGemini Advancedのような大規模モデルは、文書の内容を深く理解できますが、月額20〜30ドルの定額制で利用回数に制限があったり、APIを使う場合は高額になったりします。大量の文書を自動処理するには不向きです。
GLM-OCRの強みは、API料金が0.2人民元(約4円)/100万トークンと非常に安価な点です。たとえば、A4サイズのスキャン画像1枚を処理するコストは1円未満です。さらに、vLLMやSGLang、Ollamaといったフレームワークに対応しており、自分のパソコンやサーバーで動かすことも可能です。継続的に大量の文書を処理する必要がある場合、ランニングコストを大幅に抑えられます。
ベンチマークでの評価
研究チームが公開したベンチマーク結果によると、GLM-OCRは複数のOCR評価データセットでトップクラスのスコアを記録しています。たとえば、OmniDocBench v1.5では94.6、OCRBenchのテキスト認識では94.0、数式認識のUniMERNetでは96.5といった数値です。ただし、表認識の一部タスク(PubTabNet)では、他のツールにわずかに劣る結果も出ています。
とはいえ、0.9Bという小型モデルでこれだけの精度を実現している点は注目に値します。GeminiやGPTのような超大型モデルと比較しても、実用レベルで十分競争力があると言えます。
フリーランスの実務でどう使えるか
GLM-OCRが実務で役立ちそうな場面をいくつか考えてみましょう。
まず、経理や事務作業の効率化です。請求書や領収書をスキャンしてアップロードすれば、日付、金額、取引先名などを自動でJSON形式に抽出してくれます。これをスプレッドシートや会計ソフトに取り込めば、手入力の手間がほぼゼロになります。月末の経費精算が10分で終わる、といった変化も十分あり得ます。
次に、翻訳業務や海外リサーチの前処理です。英語や中国語の論文、契約書、マニュアルなどをPDF形式で受け取った際、まずGLM-OCRでMarkdown形式に変換してから翻訳ツールに渡せば、レイアウトを保ったまま効率的に作業できます。特に数式や表が多い技術文書では、従来のコピー&ペーストでは構造が崩れてしまうため、この工程が重要です。
また、過去の紙資料や手書きメモのデジタル化にも使えます。古い契約書、顧客情報、プロジェクトノートなどをスキャンして一括処理すれば、検索可能なテキストデータとして保管できます。リモートワークが増えた今、紙の資料を持ち歩かずに済むのは大きなメリットです。
導入する際の注意点
現時点で公開されている情報では、GLM-OCRのAPIやモデルがどの程度一般ユーザーに開放されているかは不明です。GitHubのリポジトリやHugging Faceのモデルページは公開されていますが、日本語のドキュメントや導入事例はまだ少ない状況です。英語の技術資料を読むのに抵抗がない方であれば、自分でセットアップして試すことは可能でしょう。
また、vLLMやOllamaで自分のマシンにインストールして使う場合、ある程度のGPUメモリが必要になる可能性があります。Macの最新モデルや、NVIDIA GPUを搭載したPCであれば動作するはずですが、古いマシンでは厳しいかもしれません。クラウドのGPUインスタンスを借りる方法もありますが、その場合はコスト計算が必要です。
精度についても、すべての文書で完璧な結果が得られるわけではありません。特に手書き文字が多い文書や、低解像度のスキャン画像では誤認識が発生する可能性があります。重要な契約書や公的書類を処理する際は、必ず目視でのチェックを入れるべきです。
フリーランスへの影響
GLM-OCRのような軽量で高精度なOCRモデルが普及すると、文書処理の自動化がさらに進みます。これまで外注していたデータ入力作業を自分で効率的に処理できるようになるため、外注費を削減しつつ納期を短縮できるでしょう。
特に、翻訳者、ライター、マーケター、経理代行などの職種では、月に数時間〜数十時間の作業時間を削減できる可能性があります。たとえば、月に100件の請求書を手入力していた場合、それが自動化されれば10時間以上の時間が浮きます。その分を新規案件の獲得や、単価の高い業務に充てられれば、収益の向上にもつながります。
一方で、単純なデータ入力業務を主な収入源にしている方にとっては、仕事が減るリスクもあります。ただし、OCRツールが完璧ではない以上、人間による最終チェックや複雑な判断が必要な場面は残ります。むしろ、OCRを使いこなして作業を効率化できる人材の需要が高まる可能性もあります。
現時点では、日本語対応の詳細や実際の精度については情報が限られているため、すぐに導入するよりも、まずは動向を追いながら試験的に使ってみる段階と言えます。英語や中国語の文書を扱う機会が多い方、技術的な興味がある方であれば、GitHubのリポジトリをチェックして試してみる価値はあるでしょう。
まとめ
GLM-OCRは、軽量ながら高精度な文書解析ができる新しいOCRモデルです。APIコストが非常に安く、自分の環境で動かすこともできるため、大量の文書を定期的に処理する必要があるフリーランスにとっては有力な選択肢になり得ます。ただし、日本語での情報や導入事例がまだ少ないため、今すぐ実務に組み込むのは難しいかもしれません。
まずは公式リポジトリやモデルページをチェックして、自分の業務に合いそうか検討してみてください。技術的なハードルが高いと感じる場合は、今後API版が使いやすくなるまで様子を見るのも一つの手です。
参考リンク:
論文:https://arxiv.org/pdf/2603.10910
GitHubリポジトリ:https://github.com/zai-org/GLM-OCR
モデルページ:https://huggingface.co/zai-org/GLM-OCR


コメント