OpenVikingが解決する課題
AIエージェントを使った開発では、長期タスクになるほどコンテキスト管理が難しくなります。従来のRAG(Retrieval-Augmented Generation)パイプラインでは、情報が断片化してしまい、必要な情報を的確に取り出せないことがありました。また、タスクが進むにつれてコンテキストの量が膨大になり、トークン使用量が増えてコストがかさむという問題もあります。
OpenVikingは、こうした課題に対して「ファイルシステムのような階層構造」というアプローチで挑んでいます。コンテキストをディレクトリとファイルのように整理することで、AIエージェントが必要な情報を効率的に探し出せるようにしています。開発元のVolcengineは、GitHubでオープンソースとして公開しており、誰でも無料で利用できます。
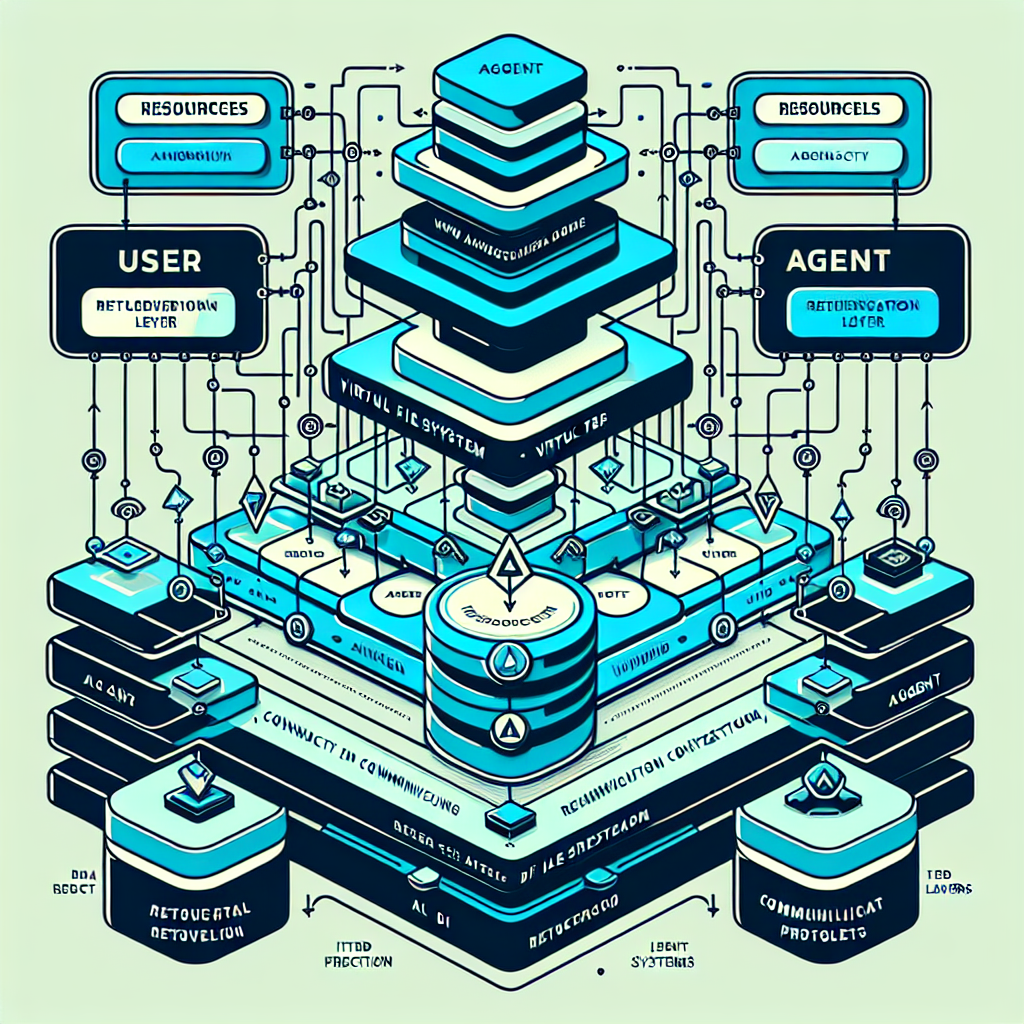
仮想ファイルシステムでコンテキストを整理
OpenVikingの最大の特徴は、「viking://」というプロトコルで公開される仮想ファイルシステムです。これは、コンピュータのフォルダ構造のようにコンテキストを分類する仕組みで、リソース、ユーザー設定、エージェントのタスクメモリなどがディレクトリにマッピングされます。
たとえば、プロジェクトドキュメントは「resources」ディレクトリに、ユーザーの好みや設定は「user」ディレクトリに、エージェントが学習したスキルやタスク履歴は「agent」ディレクトリに格納されます。エージェントは「ls」や「find」といったコマンドを使って、まるでファイルを探すようにコンテキストを検索できます。
この設計により、AIエージェントは必要な情報を確実に見つけられるようになります。従来のフラットな検索では、関連性の低い情報まで拾ってしまうことがありましたが、ディレクトリ構造を使うことで検索精度が向上します。
階層的な検索とコンテキスト読み込み
OpenVikingには「ディレクトリ再帰検索」という機能があります。これは、まずベクトル検索でスコアの高いディレクトリを特定し、そのディレクトリ内でさらに詳細な検索を行う仕組みです。必要に応じてサブディレクトリへ再帰的に掘り下げていくため、ローカルな関連性とグローバルなコンテキスト構造の両方を保ちながら、効率的に情報を取得できます。
さらに、コンテキストの読み込みは3段階の階層に分かれています。L0は一文の要約で素早い検索用、L1は概要でコア情報と使用シナリオを含む計画用、L2は完全な元のコンテンツで詳細な読み取り用です。これらは「.abstract」や「.overview」といったファイルとしてディレクトリに関連付けられ、必要に応じて段階的に読み込まれます。
この仕組みにより、プロンプトの肥大化を防げます。エージェントは最初に要約だけを読み込み、必要なら詳細を取得するという流れで動くため、無駄なトークンを消費しません。これは長期タスクでコストを抑えるうえで大きなメリットです。
セッション管理と学習機能
OpenVikingは、セッションが終了するたびに自動でメモリを抽出する機能を備えています。タスクの実行結果やユーザーからのフィードバックを分析し、ユーザーメモリとエージェントメモリのディレクトリを更新します。これにより、エージェントはユーザーの好みやツールの使い方のコツを学習し、次回以降のタスクで活かせるようになります。
たとえば、あるユーザーが特定の形式のレポートを好む場合、エージェントはその設定を記憶し、次回から自動で同じ形式を適用できます。また、エージェント自身も過去の実行パターンを蓄積し、効率的な動作を学んでいきます。
検索プロセスの可視化
OpenVikingには検索の軌跡を保存し可視化する機能もあります。ディレクトリのブラウジングやファイルの位置特定の過程を記録することで、コンテキストルーティングに問題があった場合にデバッグしやすくなります。これはエージェント開発者にとって、システムの挙動を理解し改善するうえで役立つ機能です。
導入方法と技術要件
OpenVikingの導入は比較的シンプルです。Python 3.10以上の環境で「pip install openviking –upgrade –force-reinstall」を実行するだけでインストールできます。対応OSはLinux、macOS、Windowsです。オプションでRust製のCLIツール「ov_cli」も利用できます。
動作には画像やコンテンツ理解用のVLMモデルと、ベクトル化・意味検索用のEmbeddingモデルが必要です。サポートされるVLMアクセスパスにはVolcengine、OpenAI、LiteLLMがあり、評価時にはOpenAIの「text-embedding-3-large」と「gpt-4-vision-preview」が使われました。
評価結果とパフォーマンス
OpenVikingの効果を示す評価結果も公開されています。LoCoMo10という長距離対話データセットで、1,540ケースのタスクを実行したところ、OpenVikingを使わない場合のタスク完了率は35.65%でしたが、OpenVikingプラグインを導入することで52.08%まで向上しました。
さらに注目すべきは、トークン使用量の削減です。OpenVikingなしでは約2,460万トークンを消費していましたが、OpenVikingを使うことで約426万トークンまで減少し、約80%の削減を実現しています。長期タスクでは特にコストへの影響が大きいため、この削減効果は実用上大きな意味を持ちます。
ただし、この評価結果はプロジェクト自身が公表したもので、独立した第三者によるベンチマークではない点には注意が必要です。実際の効果は、使用するモデルやタスクの種類によって変わる可能性があります。
フリーランスエンジニアへの影響
OpenVikingは、AIエージェントを活用したシステム開発に携わるフリーランスエンジニアにとって、新しい選択肢となります。特に、顧客向けにチャットボットや業務自動化エージェントを構築している方には、コンテキスト管理の改善とコスト削減の両面でメリットがあります。
たとえば、長期間にわたって顧客とやり取りするカスタマーサポートエージェントを開発する場合、従来は会話履歴が膨大になるとトークンコストが跳ね上がりました。OpenVikingを使えば、必要な情報だけを段階的に読み込むことでコストを抑えられます。また、ユーザーごとの設定や好みを階層的に管理できるため、パーソナライズされた応答も実現しやすくなります。
一方で、OpenVikingはまだ比較的新しいプロジェクトです。バージョンは0.1.18と初期段階にあり、今後仕様が変わる可能性もあります。本格的なプロダクション環境で使う前に、小規模なプロトタイプで試してみるのが安全でしょう。
また、導入にはVLMモデルやEmbeddingモデルの設定が必要なため、ある程度の技術的な知識が求められます。AIエージェント開発の経験がある方なら問題ないでしょうが、初心者には少しハードルが高いかもしれません。
まとめ
OpenVikingは、AIエージェントのコンテキスト管理を改善するオープンソースツールです。ファイルシステムのような階層構造でメモリやリソースを整理し、検索精度の向上とトークン使用量の削減を実現しています。エージェント開発に携わるフリーランスエンジニアで、長期タスクのコスト削減やコンテキスト管理に課題を感じている方は、試してみる価値があるでしょう。
ただし、まだ初期バージョンのため、いきなり本番環境で使うのではなく、まずは小規模なプロジェクトで動作を確認することをおすすめします。GitHubリポジトリ(https://github.com/volcengine/OpenViking)でドキュメントやサンプルコードを確認しながら、自分のプロジェクトに合うかどうか判断してみてください。


コメント